Kubernetes 是一个可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,方便进行声明式配置和自动化。Kubernetes 拥有一个庞大且快速增长的生态系统,其服务、支持和工具的使用范围广泛。
此页面是 Kubernetes 的概述。
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。K8s 这个缩写是因为 K 和 s 之间有 8 个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。
为什么需要 Kubernetes,它能做什么?
容器是打包和运行应用程序的好方式。在生产环境中, 你需要管理运行着应用程序的容器,并确保服务不会下线。 例如,如果一个容器发生故障,则你需要启动另一个容器。 如果此行为交由给系统处理,是不是会更容易一些?
这就是 Kubernetes 要来做的事情! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移你的应用、提供部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary (金丝雀) 部署。
Kubernetes 为你提供:
- 批处理执行 除了服务外,Kubernetes 还可以管理你的批处理和 CI(持续集成)工作负载,如有需要,可以替换失败的容器。
- 水平扩缩 使用简单的命令、用户界面或根据 CPU 使用率自动对你的应用进行扩缩。
- IPv4/IPv6 双栈 为 Pod(容器组)和 Service(服务)分配 IPv4 和 IPv6 地址。
- 为可扩展性设计 在不改变上游源代码的情况下为你的 Kubernetes 集群添加功能。
Kubernetes 不是什么
Kubernetes 不是传统的、包罗万象的 PaaS(平台即服务)系统。 由于 Kubernetes 是在容器级别运行,而非在硬件级别,它提供了 PaaS 产品共有的一些普遍适用的功能, 例如部署、扩展、负载均衡,允许用户集成他们的日志记录、监控和警报方案。 但是,Kubernetes 不是单体式(monolithic)系统,那些默认解决方案都是可选、可插拔的。 Kubernetes 为构建开发人员平台提供了基础,但是在重要的地方保留了用户选择权,能有更高的灵活性。
Kubernetes:
- 不限制支持的应用程序类型。 Kubernetes 旨在支持极其多种多样的工作负载,包括无状态、有状态和数据处理工作负载。 如果应用程序可以在容器中运行,那么它应该可以在 Kubernetes 上很好地运行。
- 不部署源代码,也不构建你的应用程序。 持续集成(CI)、交付和部署(CI/CD)工作流取决于组织的文化和偏好以及技术要求。
- 不提供应用程序级别的服务作为内置服务,例如中间件(例如消息中间件)、 数据处理框架(例如 Spark)、数据库(例如 MySQL)、缓存、集群存储系统 (例如 Ceph)。这样的组件可以在 Kubernetes 上运行,并且/或者可以由运行在 Kubernetes 上的应用程序通过可移植机制(例如开放服务代理)来访问。
- 不是日志记录、监视或警报的解决方案。 它集成了一些功能作为概念证明,并提供了收集和导出指标的机制。
- 不提供也不要求配置用的语言、系统(例如 jsonnet),它提供了声明性 API, 该声明性 API 可以由任意形式的声明性规范所构成。
- 不提供也不采用任何全面的机器配置、维护、管理或自我修复系统。
- 此外,Kubernetes 不仅仅是一个编排系统,实际上它消除了编排的需要。 编排的技术定义是执行已定义的工作流程:首先执行 A,然后执行 B,再执行 C。 而 Kubernetes 包含了一组独立可组合的控制过程,可以持续地将当前状态驱动到所提供的预期状态。 你不需要在乎如何从 A 移动到 C,也不需要集中控制,这使得系统更易于使用且功能更强大、 系统更健壮,更为弹性和可扩展。
Kubernetes 的历史背景
让我们回顾一下为何 Kubernetes 能够裨益四方。
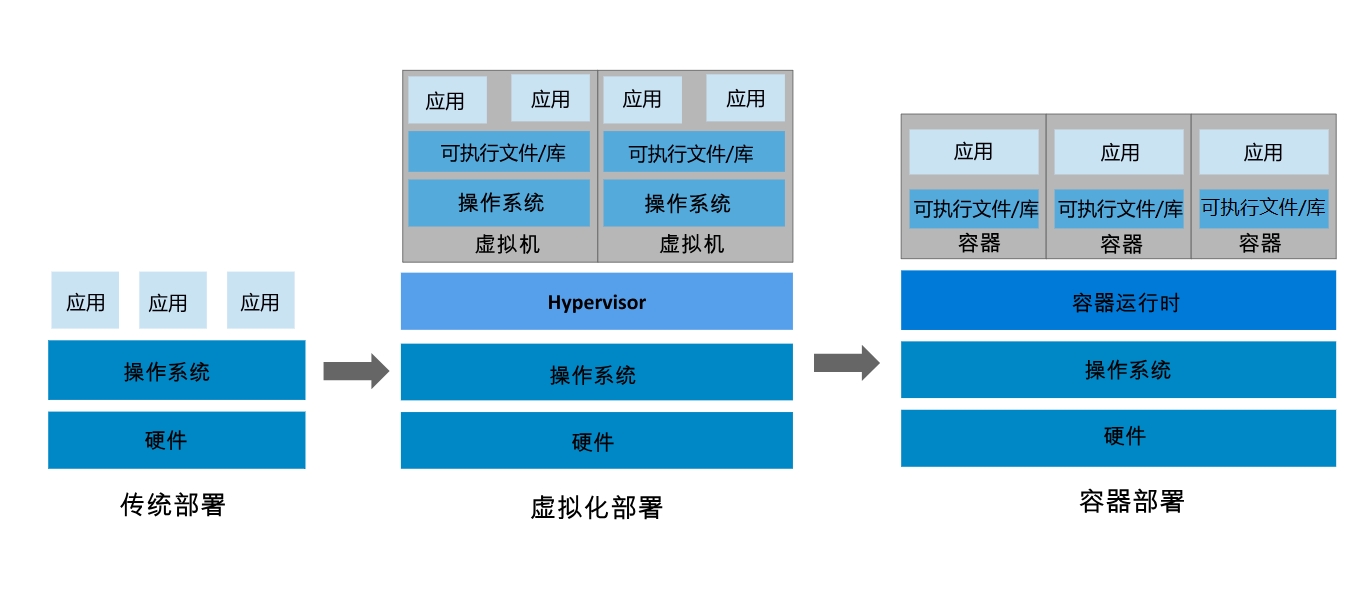
传统部署时代:
早期,各个组织是在物理服务器上运行应用程序。 由于无法限制在物理服务器中运行的应用程序资源使用,因此会导致资源分配问题。 例如,如果在同一台物理服务器上运行多个应用程序, 则可能会出现一个应用程序占用大部分资源的情况,而导致其他应用程序的性能下降。 一种解决方案是将每个应用程序都运行在不同的物理服务器上, 但是当某个应用程序资源利用率不高时,剩余资源无法被分配给其他应用程序, 而且维护许多物理服务器的成本很高。
虚拟化部署时代:
因此,虚拟化技术被引入了。虚拟化技术允许你在单个物理服务器的 CPU 上运行多台虚拟机(VM)。 虚拟化能使应用程序在不同 VM 之间被彼此隔离,且能提供一定程度的安全性, 因为一个应用程序的信息不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器的资源,并且因为可轻松地添加或更新应用程序, 而因此可以具有更高的可扩缩性,以及降低硬件成本等等的好处。 通过虚拟化,你可以将一组物理资源呈现为可丢弃的虚拟机集群。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是更宽松的隔离特性,使容器之间可以共享操作系统(OS)。 因此,容器比起 VM 被认为是更轻量级的。且与 VM 类似,每个容器都具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来,例如:
- 敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
- 持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性), 提供可靠且频繁的容器镜像构建和部署。
- 关注开发与运维的分离:在构建、发布时创建应用程序容器镜像,而不是在部署时, 从而将应用程序与基础架构分离。
- 可观察性:不仅可以显示 OS 级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
- 跨开发、测试和生产的环境一致性:在笔记本计算机上也可以和在云中运行一样的应用程序。
- 跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
- 以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
- 松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 – 而不是在一台大型单机上整体运行。
- 资源隔离:可预测的应用程序性能。
- 资源利用:高效率和高密度。
更多请参考:https://kubernetes.io/zh-cn/docs/concepts/overview/

近期评论