逻辑表与实际表之间的对应关系,均匀分布
使用sharding-jdbc来实现无论是读写分离,还是分库分表,都是很简单易用的。
如下图,其中order被拆分为两个表:
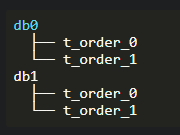
//使用默认的分表配置
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable(“t_order”);
orderTableRuleConfig.setActualDataNodes(“db0.t_order_0, db0.t_order_1, db1.t_order_0, db1.t_order_1″);
LogicTable and ActualTable
数据库分库分表的目的是将数据从原始表传播到不同数据库中的不同表,并在不更改原始sql的情况下查询数据。
这种映射关系将通过使用LogicTable和ActualTable来说明。假设使用PreparedStatement访问数据库,SQL如下:
select * from t_order where user_id = ? and order_id = ?;
当条件user_id = 0 并且 order_id= 0时,Sharding-JDBC会改变这个SQL为以下目标SQL:
select * from db0.t_order_0 where user_id = ? and order_id = ?;
第一个SQL中的t_order是LogicTable和db0。第二个SQL中的t_order_0是ActualTable。
规则配置
我们可以通过配置规则来实现上述功能,本部分将介绍详细的规则配置:
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration(); shardingRuleConfig.getTableRuleConfigs().add(orderTableRule);
shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRule);
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“user_id”, “xxx.ModuloDatabaseShardingAlgorithm”));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“order_id”, “xxx.ModuloTableShardingAlgorithm”));
数据源配置
我们需要创建至少一个数据源映射对象,用于描述数据源名称和数据源的映射。如果使用了分库,那么是需要两个创建两个BasicDataSource对象:
private BasicDataSource dataSource1() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/db0?serverTimezone=GMT&characterEncoding=utf8");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setInitialSize(0);
dataSource.setMaxIdle(5);
dataSource.setMinIdle(100);
dataSource.setMaxOpenPreparedStatements(100);
dataSource.setTestWhileIdle(true);
dataSource.setValidationQuery("SELECT 1");
dataSource.setTimeBetweenEvictionRunsMillis(3600000);
dataSource.setMinEvictableIdleTimeMillis(18000000);
dataSource.setTestOnBorrow(true);
dataSource.setMaxWaitMillis(300000);
return dataSource;
}
private BasicDataSource dataSource2() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/db1?serverTimezone=GMT&characterEncoding=utf8");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setInitialSize(0);
dataSource.setMaxIdle(5);
dataSource.setMinIdle(100);
dataSource.setMaxOpenPreparedStatements(100);
dataSource.setTestWhileIdle(true);
dataSource.setValidationQuery("SELECT 1");
dataSource.setTimeBetweenEvictionRunsMillis(3600000);
dataSource.setMinEvictableIdleTimeMillis(18000000);
dataSource.setTestOnBorrow(true);
dataSource.setMaxWaitMillis(300000);
return dataSource;
}
以下是数据源集合的代码:
Map<String, DataSource> dataSourceMap = new HashMap<>();
dataSourceMap.put(“ds_0″, datasource1());
dataSourceMap.put(“ds_1″, datasource());
*注:如果只是为了分表,那么无需创建两个数据源,但是如果你想实现读写分离或者是分库,那么则需要至少个数据源。
策略配置
一共有两个策越,分表是针对数据库跟数据库表
在sharding-jdbc中有两个用于分库分表的策略:
- DatabaseShardingStrategy
- TableShardingStrategy
DatabaseShardingStrategy用于分布式数据库的数据源的策略。
TableShardingStrategy用于分布数据库表的策略。
此外,这两种策略的API是相同的,因此我们只要对其中一种API进行详细的介绍就可以了。
特定表规则的全局默认策略
策略与数据表(t_order)规则密切相关,因为策略适用于特定的表规则。
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable(“t_order”);
orderTableRuleConfig.setActualDataNodes(“ds_0.t_order_0, ds_0.t_order_1, ds_1.t_order_0, ds_1.t_order_1″);
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“user_id”, “xxx.ModuloDatabaseShardingAlgorithm”));
orderTableRuleConfig.setTableShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“order_id”, “xxx.ModuloTableShardingAlgorithm”));
上述的代码,有两种策略,第一种就是通过user_id进行数据库的分配;第二种就是根据order_id再对数据表进行分配。最终实现的逻辑代码其实是:xxx.ModuloDatabaseShardingAlgorithm、xxx.ModuloTableShardingAlgorithm。
如果所有或大部分数据表都使用相同的分片策略,则可以使用默认策略来简化配置。
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();//第个表的策略
orderTableRuleConfig.setLogicTable(“t_order”);
orderTableRuleConfig.setActualDataNodes(“ds_0.t_order_0, ds_0.t_order_1, ds_1.t_order_0, ds_1.t_order_1″);
TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration();//第二个表的策略
orderItemTableRuleConfig.setLogicTable(“t_order_item”);
orderItemTableRuleConfig.setActualDataNodes(“ds_0.t_order_item_0,ds_0.t_order_item_1,ds_1.t_order_item_0,ds_1.t_order_item_1″);
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRuleConfig);
shardingRuleConfig.setDefaultDatabaseShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“user_id”, “xxx.ModuloDatabaseShardingAlgorithm”));
shardingRuleConfig.setDefaultTableShardingStrategyConfig(new ComplexShardingStrategyConfiguration(“order_id”, “xxx.ModuloTableShardingAlgorithm”));
上述代码其实跟前一段是一致的,但是因为配置了两个数据表的分配策略,所以创建了两个TableRuleConfiguration,然后通过ShardingRuleConfiguration的方法getTableRuleConfigs().add()把规则添加进去。
分表或分库的列字段
分片策略中设置为第一个参数为分库分表的列字段(user_id、order_id)是SQL中WHERE中的条件列。如果你的SQL语句的WHERE中可能会没有这两个列字段,那么你最好在xxx.ModuloDatabaseShardingAlgorithm、xxx.ModuloTableShardingAlgorithm逻辑代码中特殊处理一下,当然你也可以配置多个分片列。
分表分库的算法(以下来自官方的翻译文件)
Sharding-JDBC provides 5 kinds of sharding strategies. Because of the closely connection between specific business and specific sharding algorithms, Sharding-JDBC not carry out sharding algorithm. Instead, after making a higher level of abstraction, we provide API to allow developers to implement sharding algorithms as they need.
Sharding-JDBC提供了5种切分策略。由于特定业务和特定的切分算法之间的紧密联系,Sharding-JDBC没有执行切分算法。相反,在进行了更高级别的抽象之后,我们提供了允许开发人员根据需要实现切分算法的API。
- StandardShardingStrategy (标准共享策略)
Support =, IN, BETWEEN AND in SQLs for sharding operation. StandardShardingStrategy only supports single sharding column, and provides two sharding algorithms of PreciseShardingAlgorithm and RangeShardingAlgorithm. The PreciseShardingAlgorithm is required to handle the sharding operation of = and IN. The RangeShardingAlgorithm is optional to handle BETWEEN AND. If the RangeShardingAlgorithm is not configured, the BETWEEN-AND SQLs will be executed in all tables.
在SQL语句中支持 =, IN, BETWEEN AND,以便进行切分操作。标准分片策略只支持单分片列,提供了两种分片算法:精确分片算法(PreciseShardingAlgorithm)和测距分片算法(RangeShardingAlgorithm)。精确分片算法(PreciseShardingAlgorithm)需要使用精确的硬件算法来处理“=”和in的切分操作。RangeShardingAlgorithm是在BETWEEN AND处理的可选方法。如果未配置RangeShardingAlgorithm,那么在查询SQL语句中,将在所有表中执行BETWEEN-AND SQLs。
- ComplexShardingStrategy(综合硬件策略)
Support =, IN, BETWEEN AND in SQLs for sharding operation. ComplexShardingStrategy supports multiple sharding columns. Due to the complex relationship among the multiple sharding columns, Sharding-JDBC only provide algorithm API to allow developers combine different sharding columns and implement the specific algorithm.
在SQL中支持 =, IN, BETWEEN AND in,以便进行切分操作。ComplexShardingStrategy 支持多个切分列。由于多个切分列之间的复杂关系,Sharding-JDBC只提供算法API,允许开发人员组合不同的切分列,实现特定的算法。
- InlineShardingStrategy (内部共享策略)
This strategy provides sharding support for =, IN in SQLs by means of Groovy’s Inline expression. InlineShardingStrategy only supports single sharding column. Some simple sharding algorithm can be configured, e.g. tuser $ {user_id% 8} shows us the t_user table is divided into 8 tables via mod(user_id), and the child tables is t_user_0 to t_user_7.
此策略通过内联表达式提供支持SQL中的 =, IN ,提供分片支持。InlineShardingStrategy 只支持单个分片的列字段。可以配置一些简单的切分算法,例如, t_user $ {user_id % 8} 向我们显示,t_user表通过取模(user_id)分为8个表,子表分别是t_user_0到t_user_7。
Support spliting table by means of Hint method, not SQL Parsing.
通过提示方法支持分表,而不对SQL进行解析。
注:这种策略不要拆分数据库或表。
联表操作
它由一组表组成,其中逻辑表和实际表之间的映射关系是相同的。例如order table与order ID进行了分割,order_item table也与order ID进行了分割,因此可以将order table与order_item table配置为彼此的BindingTable。
在这种情况下,SQL语句应该如下:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.user_id=? AND o.order_id=?
t_order位于FROM的左侧,Sharding-JDBC将它视为绑定表的驱动表。所有计算将只使用已配置的驱动表策略。因此,t_order_item的路由计算也将使用t_order的条件。这个实现的核心在于它们相同的分片列。
最后提交我的实验代码:
@Configuration
@EnableTransactionManagement
@MapperScan(value = "com.lanxinbase.repository.mapper")
public class MybatisConfig implements TransactionManagementConfigurer {
@Resource
private ShardingDataSource shardingDataSource;
public MybatisConfig(){
}
@Bean(value = "sessionFactoryBean")
public SqlSessionFactoryBean sessionFactoryBean() throws Exception {
SqlSessionFactoryBean factoryBean = new SqlSessionFactoryBean();
factoryBean.setDataSource(shardingDataSource);
factoryBean.setConfiguration(this.getConfiguration());
String locationPattern = ResourcePatternResolver.CLASSPATH_URL_PREFIX + "com/lanxinbase/repository/resource/**.xml";
PathMatchingResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
factoryBean.setMapperLocations(resolver.getResources(locationPattern));
return factoryBean;
}
@Bean
public SqlSessionTemplate sqlSessionTemplate(SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
@Override
public PlatformTransactionManager annotationDrivenTransactionManager() {
DataSourceTransactionManager manager = new DataSourceTransactionManager();
manager.setDataSource(shardingDataSource);
manager.setDefaultTimeout(40);
manager.setRollbackOnCommitFailure(true);
return manager;
}
public org.apache.ibatis.session.Configuration getConfiguration() {
org.apache.ibatis.session.Configuration configuration = new org.apache.ibatis.session.Configuration();
configuration.setLogImpl(StdOutImpl.class);
configuration.setLocalCacheScope(LocalCacheScope.SESSION);
configuration.setCacheEnabled(true);
return configuration;
}
@Bean
public ShardingDataSource shardingDataSource() throws SQLException {
ShardingRuleConfiguration conf = new ShardingRuleConfiguration();
/**
* 添加分表策略
*/
conf.getTableRuleConfigs().add(tableRuleConfiguration());
conf.getBindingTableGroups().add(Constant.SHARDING_TABLE_GPS);
//http://shardingsphere.apache.org/document/legacy/2.x/en/02-guide/master-slave/
//conf.getMasterSlaveRuleConfigs().add();配置读写分离
//这个是分库的
//conf.setDefaultDatabaseShardingStrategyConfig(new StandardShardingStrategyConfiguration("age", ShardingPreciseShardingAlgorithm.class.getName()));
/**
* 分表处理对象类
*/
conf.setDefaultTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("imei", ShardingPreciseShardingAlgorithm.class.getName()));
conf.build(this.getDataSourceMap());
ShardingDataSource dataSource = new ShardingDataSource(conf.build(this.getDataSourceMap()));
return dataSource;
}
/**
* 数据表配置,我这里只做了分表
* 如果有多个表,就重复创建tableRuleConfiguration方法,
* 然后通过getTableRuleConfigs.add(tableRuleConfiguration());
*
* @return
*/
@Bean
public TableRuleConfiguration tableRuleConfiguration() {
TableRuleConfiguration ruleConfiguration = new TableRuleConfiguration();
/**
* 要逻辑表
*/
ruleConfiguration.setLogicTable(Constant.SHARDING_TABLE_GPS);
/**
* 区分规则
*/
ruleConfiguration.setActualDataNodes("dataSource2.lx_dev_gps_${0..9}");
/**
* 用于区分的字段
*/
ruleConfiguration.setKeyGeneratorColumnName("imei");
return ruleConfiguration;
}
/**
* 可以配置多个dataSource,如dataSource1、dataSource2
* 然后就可以把读写分离分开了
* @return
*/
private Map<String, DataSource> getDataSourceMap() {
Map<String, DataSource> result = new HashMap<>();
result.put("dataSource2", this.dataSource2());
return result;
}
/**
* 创建一个BasicDataSource给sharding-jdbc
* @return
*/
private BasicDataSource dataSource2() {
BasicDataSource dataSource = new BasicDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://127.0.0.1:3306/test?serverTimezone=GMT&characterEncoding=utf8");
dataSource.setUsername("root");
dataSource.setPassword("root");
dataSource.setInitialSize(0);
dataSource.setMaxIdle(5);
dataSource.setMinIdle(100);
dataSource.setMaxOpenPreparedStatements(100);
dataSource.setTestWhileIdle(true);
dataSource.setValidationQuery("SELECT 1");
dataSource.setTimeBetweenEvictionRunsMillis(3600000);
dataSource.setMinEvictableIdleTimeMillis(18000000);
dataSource.setTestOnBorrow(true);
dataSource.setMaxWaitMillis(300000);
return dataSource;
}
}
//这里才是最终处理分表的逻辑代码
public class ShardingPreciseShardingAlgorithm implements PreciseShardingAlgorithm<Integer> {
private static final Logger logger = Logger.getLogger(ShardingPreciseShardingAlgorithm.class.getName());
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Integer> shardingValue) {
int flag = shardingValue.getValue() % 10;
//只对特别的表进行拦截处理
if (shardingValue.getLogicTableName().contains(Constant.SHARDING_TABLE_GPS)){
for (String tableName : availableTargetNames) {
if (tableName.endsWith(flag + "")) {
logger.info(">>>>tableName:" + tableName);
if (flag == 0) {
return tableName.substring(0, tableName.lastIndexOf("_"));
}
return tableName;
}
}
throw new IllegalArgumentException("No match to the table.");
}
return shardingValue.getLogicTableName();
}
}
*注:本人只做了分表的策略,没有做分库,是用于存放硬件设备GPS数据的表,一共10个。
更多文献:http://shardingsphere.apache.org/document/legacy/2.x/en/02-guide/sharding/



近期评论