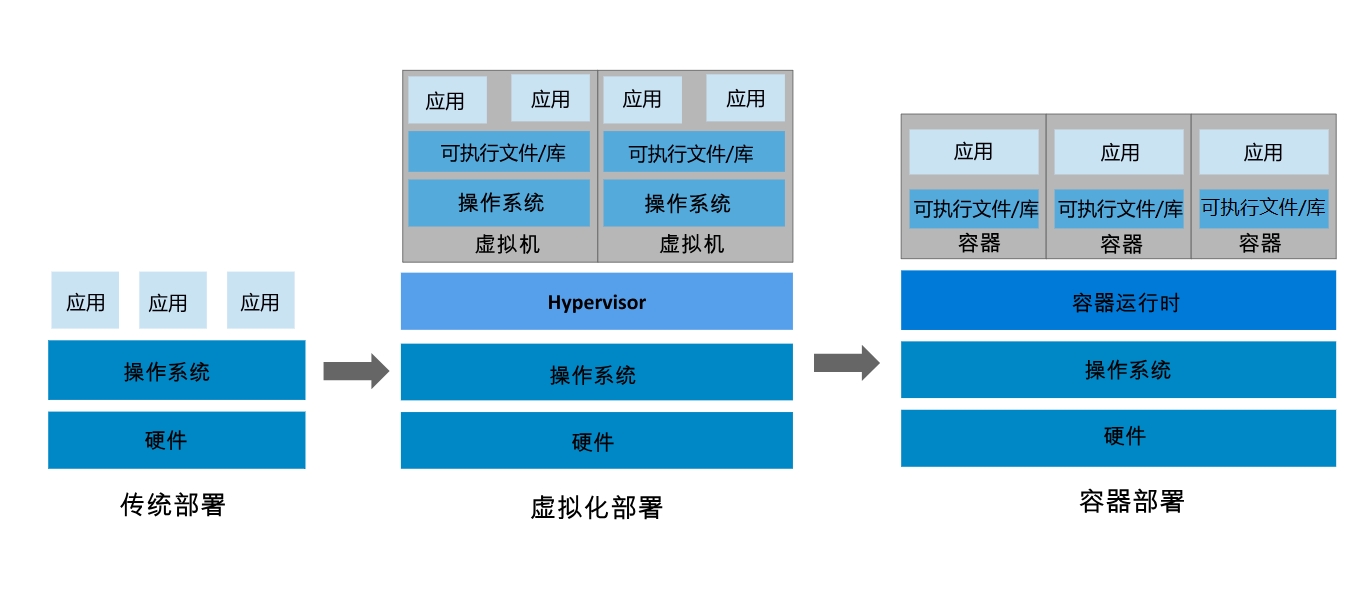
Kubernetes 这个名字源于希腊语,意为“舵手”或“飞行员”。K8s 这个缩写是因为 K 和 s 之间有 8 个字符的关系。 Google 在 2014 年开源了 Kubernetes 项目。 Kubernetes 建立在 Google 大规模运行生产工作负载十几年经验的基础上, 结合了社区中最优秀的想法和实践。
function isMobile() {
return /Mobi|Android|iPhone/i.test(navigator.userAgent);
}
2. 获取元素距离页面顶部的距离
function getOffsetTop(el) {
let offset = 0;
while (el) {
offset += el.offsetTop;
el = el.offsetParent;
}
return offset;
}
3. 防抖函数 debounce
function debounce(fn, delay = 300) {
let timer;
return function (...args) {
clearTimeout(timer);
timer = setTimeout(() => fn.apply(this, args), delay);
};
}
4. 节流函数 throttle
function throttle(fn, delay = 300) {
let last = 0;
return function (...args) {
const now = Date.now();
if (now - last > delay) {
last = now;
fn.apply(this, args);
}
};
}
5. 复制文本到剪贴板
function copyToClipboard(text) {
navigator.clipboard.writeText(text);
}
6. 平滑滚动到页面顶部
function scrollToTop() {
window.scrollTo({top: 0, behavior: 'smooth'});
}
function unique(arr) {
return [...new Set(arr)];
}
9. 生成随机颜色
function randomColor() {
return `#${Math.random().toString(16).slice(2, 8)}`;
}
10. 获取 URL 查询参数
function getQueryParam(name) {
return new URLSearchParams(window.location.search).get(name);
}
11. 判断是否为闰年
function isLeapYear(year) {
return (year % 4 === 0 && year % 100 !== 0) || year % 400 === 0;
}
12. 数组乱序(洗牌算法)
function shuffle(arr) {
for (let i = arr.length - 1; i > 0; i--) {
const j = Math.floor(Math.random() * (i + 1));
[arr[i], arr[j]] = [arr[j], arr[i]];
}
return arr;
}
13. 获取 cookie
function getCookie(name) {
const match = document.cookie.match(new RegExp('(^| )' + name + '=([^;]+)'));
return match ? decodeURIComponent(match[2]) : null;
}
14. 设置 cookie
function setCookie(name, value, days = 7) {
const d = new Date();
d.setTime(d.getTime() + days * 24 * 60 * 60 * 1000);
document.cookie = `${name}=${encodeURIComponent(value)};expires=${d.toUTCString()};path=/`;
}
15. 删除 cookie
function deleteCookie(name) {
setCookie(name, '', -1);
}
function getTimeString() {
return new Date().toLocaleString();
}
18. 监听元素尺寸变化(ResizeObserver)
const ro = new ResizeObserver(entries => {
for (let entry of entries) {
console.log('size changed:', entry.contentRect);
}
});
ro.observe(document.querySelector('#app'));
19. 判断浏览器类型
function getBrowser() {
const ua = navigator.userAgent;
if (/chrome/i.test(ua)) return 'Chrome';
if (/firefox/i.test(ua)) return 'Firefox';
if (/safari/i.test(ua)) return 'Safari';
if (/msie|trident/i.test(ua)) return 'IE';
return 'Unknown';
}

















近期评论