开源产品:Rsyslog、Kafka、ELK
处理流程为:Vm Rsyslog–> Rsyslog Server –omkafka–> Kafka –> Logstash –> Elasticsearch –> Kibana
ps:omkafka模块在rsyslog v8.7.0之后的版本才支持
环境:
| ELK SERVER |
10.10.27.123 |
| Rsyslog Server |
10.10.27.121 |
| Rsyslog client |
10.10.27.122 |
rsyslog日志收集
Rsyslog是高速的日志收集处理服务,它具有高性能、安全可靠和模块化设计的特点,能够接收来自各种来源的日志输入(例如:file,tcp,udp,uxsock等),并通过处理后将结果输出的不同的目的地(例如:mysql,mongodb,elasticsearch,kafka等),每秒处理日志量能够超过百万条。
Rsyslog作为syslog的增强升级版本已经在各linux发行版默认安装了,无需额外安装
1、rsyslog服务端
~]
$ModLoad imudp
$UDPServerRun 514
$ModLoad imtcp
$InputTCPServerRun 514
~]
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
$template myFormat,"%timestamp% %fromhost-ip% %syslogtag% %msg%\n"
$ActionFileDefaultTemplate myFormat
$template RemoteLogs,"/data/rsyslog/%fromhost-ip%/%fromhost-ip%_%$YEAR%-%$MONTH%-%$DAY%.log"
:fromhost-ip, !isequal, "127.0.0.1" ?RemoteLogs
~]
为了把rsyslog server收集的日志数据导入到ELK中,需要在rsyslog server使用到omkafka的模块
~]
~]
module(load="omkafka")
module(load="imfile")
template(name="SystemlogTemplate" type="string" string="%hostname%<-+>%syslogtag%<-+>%msg%\n")
ruleset(name="systemlog-kafka") {
action (
type="omkafka"
template="SystemlogTemplate"
topic="system-log"
broker="10.10.27.123:9092"
)
}
input(type="imfile" Tag="Systemlog" File="/data/rsyslog/*/*.log" Ruleset="systemlog-kafka"
~]
2、 Rsyslog客户端
~]
*.* @10.10.27.121:514
~]
至此,rsyslog准备完毕,验证/data/rsyslog下是否产生日志文件
kafka搭建
1、搭建kafka依赖的zookeeper
~]
~]
~]
~]
--name zookeeper \
--net=host \
-p 2181:2181 \
--restart always \
-v /data/zookeeper:/data/zookeeper \
-e ZOO_PORT=2181 \
-e ZOO_DATA_DIR=/data/zookeeper/data \
-e ZOO_DATA_LOG_DIR=/data/zookeeper/logs \
-e ZOO_MY_ID=1 \
-e ZOO_SERVERS="server.1=10.10.27.123:2888:3888" \
wurstmeister/zookeeper:latest
参数说明:
--net=host: 容器网络设置为 host, 能够和宿主机共享网络
-p 2181:2181: 容器的 2181 端口映射到宿主机的 2181 端口
-v /data/zookeeper:/data/zookeeper:容器的/data/zookeeper 目录挂载到宿主机的 /data/zookeeper 目录
ZOO_PORT:zookeeper 的运行端口
ZOO_DATA_DIR:数据存放目录
ZOO_DATA_LOG_DIR: 日志存放目录
ZOO_MY_ID:zk 的节点唯一标识
ZOO_SERVERS:zk 集群服务配置
如果需要部署zookeeper集群:其他 2 个节点同理部署, 只需要修改 ZOO_MY_ID; 节点 2:ZOO_MY_ID=2,节点 3:ZOO_MY_ID=3
验证
~]
bash
bash
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.13/bin/../conf/zoo.cfg
Mode: standalone
2、搭建kafka
~]
~]
~]
--name kafka \
--net=host \
--restart always \
-v /data:/data \
-e KAFKA_BROKER_ID=1 \
-e KAFKA_PORT=9092 \
-e KAFKA_HEAP_OPTS="-Xms1g -Xmx1g" \
-e KAFKA_HOST_NAME=10.10.27.123 \
-e KAFKA_ADVERTISED_HOST_NAME=10.10.27.123 \
-e KAFKA_LOG_DIRS=/data/kafka \
-e KAFKA_ZOOKEEPER_CONNECT="10.10.27.123:2181" \
wurstmeister/kafka:latest
参数说明:
--net=host: 容器网络设置为 host, 能够和宿主机共享网络
-v /data:/data:容器的/data 目录挂载到宿主机的 /data 目录
KAFKA_BROKER_ID:kafka 的 broker 集群标识, 每台节点 broker 不一样
KAFKA_PORT:kafka 运行端口
KAFKA_HEAP_OPTS:kafka 启动时的 jvm 大小
KAFKA_HOST_NAME:kafka 主机名称,这里随便写,但是要与主机 IP 做 dns 映射
KAFKA_LOG_DIRS:kafka 日志存储目录
KAFKA_ZOOKEEPER_CONNECT:kafka 运行在 zk 里面,zk 提供的连接地址,集群的话写多个地址,逗号隔开
如果需要部署zookeeper集群:其他 2 个节点同理部署, 只需要修改 KAFKA_BROKER_ID、KAFKA_HOST_NAME、KAFKA_ADVERTISED_HOST_NAME 对应的值即可
验证
进入 kafka 容器
~]
bash-4.4
__consumer_offsets
log-api
system-log
ELK搭建
1、搭建elasticsearch
~]
~]
~]
~]
cluster.name: es-cluster
network.host: 10.10.27.123
http.cors.enabled: true
http.cors.allow-origin: "*"
network.publish_host: 10.10.27.123
discovery.zen.minimum_master_nodes: 1
discovery.zen.ping.unicast.hosts: ["10.10.27.123"]
discovery.type: single-node
多节点集群使用以下配置:
~]
cluster.name: es-cluster
network.host: 0.0.0.0
node.name: master
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
network.publish_host: 192.168.1.140
discovery.zen.ping.unicast.hosts: ["192.168.1.140,192.168.1.142,192.168.1.147"]
discovery.zen.minimum_master_nodes: 1
~]
--name=elasticsearch -p 9200:9200 -p 9300:9300 -p 5601:5601 \
--net=host \
--restart always \
-e ES_JAVA_OPTS="-Xms1g -Xmx1g" \
-v /data/es/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/es/data:/usr/share/elasticsearch/data \
elasticsearch:7.7.0
启动过程会有报错,提前做以下操作
~]
~]
~]
vm.max_map_count=655350
~]
如果需要部署zookeeper集群:其他 2 个节点同样的部署思路,只需要修改 elasticsearch 的配置文件中的 node.name 和 network.publish_host
2、部署kibana
~]
~]
~]
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://10.10.27.123:9200"]
i18n.locale: "zh-CN"
xpack.security.enabled: false
ps:多集群可忽略此配置文件,使用默认即可
~]
--restart always \
--name kibana \
--network=container:elasticsearch \
-v /data/kibana/config:/usr/share/kibana/config \
daocloud.io/library/kibana:7.7.0
3、部署logstash
~]
~]
~]
input{
kafka{
topics => ["system-log"]
bootstrap_servers => ["10.10.27.123:9092"]
}
}
output{
elasticsearch {
hosts => ["10.10.27.123:9200"]
index => "system-log-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
~]
--restart always \
--name logstash \
--net=host \
--link elasticsearch \
-v /data/logstash/conf/logstash.conf:/usr/share/logstash/pipeline/logstash.conf \
daocloud.io/library/logstash:7.7.0
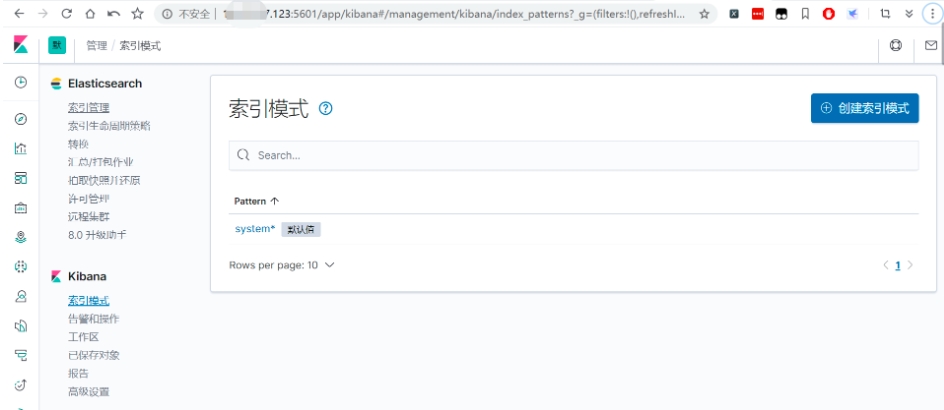
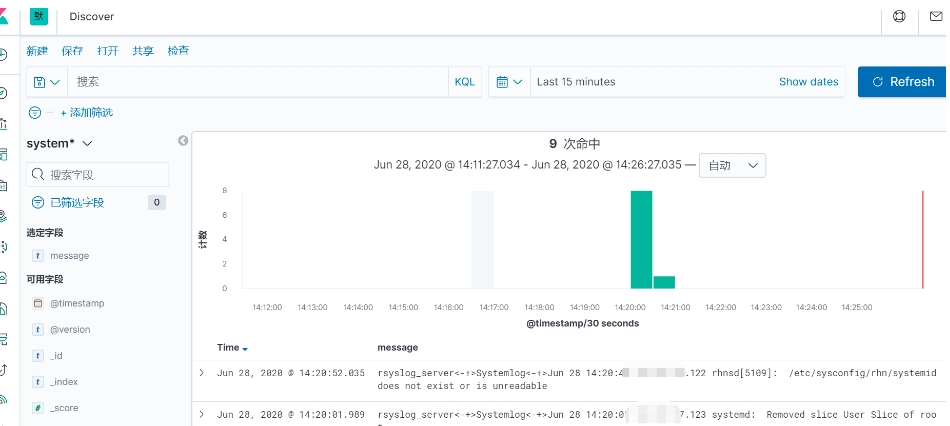
kibana添加索引
镜像下载
由于中国下载docker镜像很慢,配置镜像仓库
--registry-mirror=https://registry.docker-cn.com
建议在本地电脑,比如win10中安装windows版docker,配置好上面镜像仓库地址(setting-Docker Engine),打开powershell进行下载打包镜像:
PS C:\Users\suixin> docker pull kibana:7.7.0
PS C:\Users\suixin> docker save -o kibana.gz kibana:7.7.0
然后上传到服务器导入:
# docker load -i kibana.gz


近期评论