容器
- Array 数组
- Slice 切片(可以看成动态的数组)
- Map 映射
一、Array 数组
- [10]int 和 [20]int 是不同类型,数组类型相同要长度和元素类型完全相同才可以
- func loopArray(arr2 [3]int) 是值传递,入参会拷贝一份数组,所以如果数组很大,从内存和性能上函数传递数组值都是很大的开销,需要避免(使用指针可以实现”引用传递” func loopArray(arr2 *[3]int),调用方传入 &arr2)
- 在 Go 中一般不直接使用数组,而是使用切片
- 数组是定长的,不可扩展,切片相当于动态数组
import "fmt"
func defineArray() [3]int {
// 定义数组,不赋初值(使用默认值)
var arr1 [5]int // [0 0 0 0 0]
// 定义数组,赋初值
arr2 := [3]int{1, 2, 3} // [1 2 3]
// 定义数组,由编译器来计算长度,不可写成[],不带长度或者 ... 的表示切片
arr3 := [...]int{4, 5, 6, 7} // [4 5 6 7]
// 创建指针数组
arr4 := [2]*string{new(string), new(string)}
*arr4[0] = "hello"
*arr4[1] = "go"
// 为指定索引位置设置值
arr5 := [3]int{1:10} // [0,10,0]
// 二维数组
var grid [4][5]int // [[0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0] [0 0 0 0 0]]
// 数组拷贝,直接复制一份 arr2 给 arr6
arr6 := arr2
fmt.Println(arr1, arr2, arr3, arr4, arr5, arr6, grid)// arr4 打印出来的是地址 [0xc00000e1e0 0xc00000e1f0]
fmt.Println(*arr4[0]) // hello
return arr2
}
// 数组是值传递,这里的入参会拷贝一份数组(使用指针可以实现"引用传递")
func loopArray(arr2 [3]int) {
// 通用方法
for i := 0; i < len(arr2); i++ {
fmt.Println(arr2[i])
}
// 最简方法,只获取数组下标
for i := range arr2 {
fmt.Println(arr2[i])
}
// 最简方法,获取数组下标和对应的值
for i, v := range arr2 {
fmt.Println(i, v)
}
// 最简方法,只获取值,使用 _ 省略变量
for _, v := range arr2 {
fmt.Println(v)
}
}
二、Slice 切片
切片是围绕动态数组的概念构建的,可以按需自动增长和缩小。切片的动态增长是通过内置函数 append 来实现的。这个函数可以快速且高效地增长切片。还可以通过对切片再次切片来缩小一个切片的大小。
切片有 3 个字段分别是指向底层数组的指针、切片访问的元素的个数(即长度)和切片允许增长到的元素个数(即容量)
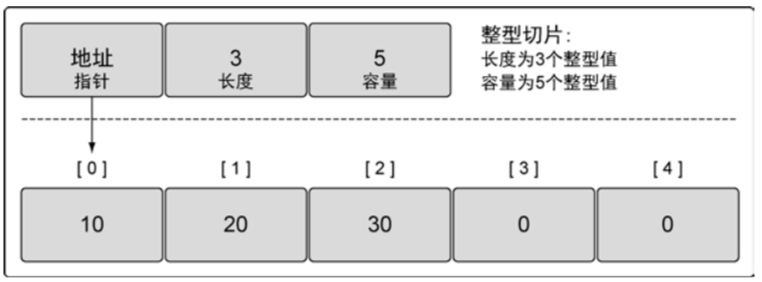
从切片 slice1 创建出来的切片 slice2,slice1 和 slice2 共享底层数组,一个修改了共享部分的元素,另一个也会感知
2.1、创建切片
// 1、使用make函数创建一个字符串切片,长度和容量都是5
slice1 := make([]string, 5)
// 2、创建一个int切片,长度是3,容量是5
slice2 := make([]int, 3, 5)
// 3、使用字面量创建切片,长度是3,容量是3
slice3 := []int{1, 2, 3} // [3]int{1, 2, 3}
// 4、创建 nil 切片,长度为0,容量为0
var slice4 []int
// 5、创建空切片,长度为0,容量为0
slice5 := make([]int, 0)
slice6 := []int{}
// 6、自定义底层数组,通过该底层数组创建切片
arr := [5]int{1, 2, 3, 4, 5}
// 数组转化为切片,左闭右开 [arr[2]~arr[4])
slice7 := arr[2:4] // [3,4]
slice8 := arr[2:] // [3,4,5]
slice9 := arr[:4] // [1,2,3,4]
slice10 := arr[:] // [1,2,3,4,5]
实际上还有第七种创建切片的方式:根据切片创建切片,称为 reslice
2.2、切片使用
slice1 := []int{1, 2, 3, 4, 5}
// 1、根据索引获取切片元素
fmt.Println(slice1[1]) // 2
// 2、根据索引修改切片元素
slice1[3] = 400
fmt.Println(slice1) // [1, 2, 3, 400, 5]
// 3、根据切片创建切片,和根据自定义数组创建切片方式相同,长度是2=3-1,容量是4=5-1
// 但是需要格外注意,新生成的切片 slice2 和原始切片 slice1 的指针元素指向了相同的底层数组,所以修改元素要注意
slice2 := slice1[1:3] // [2, 3]
slice2[1] = 300
fmt.Println(slice2) // [2, 300]
fmt.Println(slice1) // [1, 2, 300, 400, 5] slice1也发生了变化
// 4、拷贝 slice 中的元素
fmt.Println("copy")
slice3 := []int{0, 0, 0, 0, 0}
slice4 := []int{1, 2, 3}
copy(slice3, slice4)
fmt.Println(slice3) // [1, 2, 3, 0, 0]
fmt.Println(slice4) // [1, 2, 3]
// 5、删除 slice 中的元素,删除slice5[2]=3
fmt.Println("delete")
slice5 := []int{1, 2, 3, 4}
slice5 = append(slice5[:2], slice5[3:]...)
fmt.Println(slice5) // [1, 2, 4]
2.3、append 增加切片长度
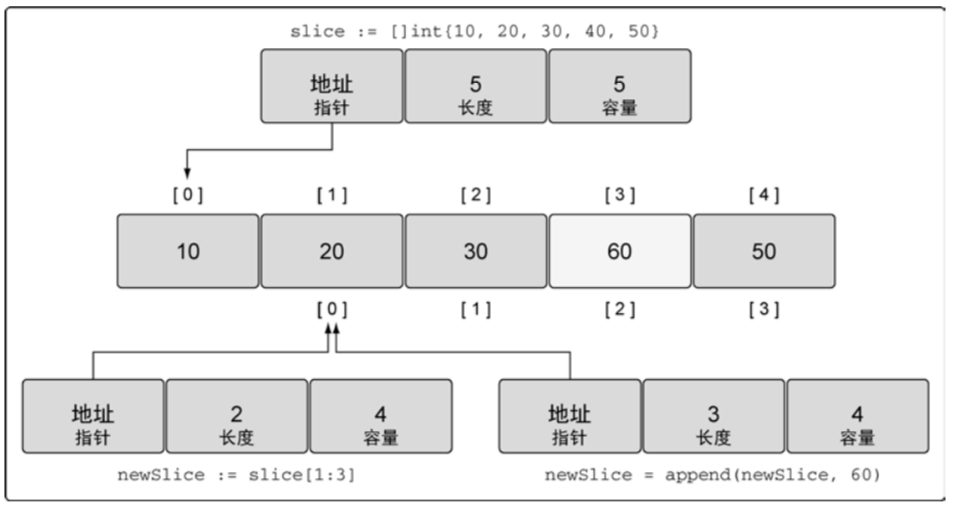
// 1、创建原始切片,长度是5,容量是5 slice := []int{10, 20, 30, 40, 50} // 2、reslice 新切片,长度是2,容量是4 newSlice := slice[1:3] // [20, 30] // 由于底层数组还有容量,可以直接追加元素而容量不变 newSlice = append(newSlice, 60) // [20, 30 ,60] 长度是3,容量是4 fmt.Println(newSlice) // [20, 30 ,60] fmt.Println(slice) // [10, 20, 30 ,60, 50]// 长度4,容量4 slice := []int{10, 20, 30, 40} // 此时切片容量用完了,再追加需要扩容,此处会新加数组,长度为原数组的2倍,即 newSlice 的底层数组是新数组,新切片容量为8; // 而 slice 的底层数组是旧数组,二者互不影响 newSlice := append(slice, 50) fmt.Println(slice) // [10, 20, 30, 40] fmt.Println(newSlice) // [10, 20, 30, 40, 50] newSlice[0] = 100 fmt.Println(slice) // [10, 20, 30, 40] fmt.Println(newSlice) // [100, 20, 30, 40, 50]
这里是我自己的测试代码:
b := make([]string, 3, 5)
b[0] = "A"
b[1] = "B"
b[2] = "C"
//b[3]="C1"
//b[4]="C2"
b_1 := append(b, "D")
b_1 = append(b, "E")
fmt.Println("b:", b)
fmt.Println("b_1:", b_1)
b1 := []int{1, 2, 3, 4, 5}
var b2 []int
b3 := b1[0:2]
fmt.Println(b1)
b1[0] = 100
fmt.Println(b2)
fmt.Println(b3)
fmt.Println(&b1[0])
fmt.Println(&b3[0])
fmt.Println(len(b3))
fmt.Println("b1:", b1)
b1_1 := append(b1, 6);
b1_2 := append(b1_1, 7);
b1_3 := append(b1_2, 8);
b1_3 = append(b1_3, 9);
b1_3 = append(b1_3, 10);
b1_3 = append(b1_3, 11);
b1_3 = append(b1_3, 12);
b1_3 = append(b1_3, 13);
b1_3 = append(b1_3, 14);
b1_3 = append(b1_3, 15);
b1_3 = append(b1_3, 16);
b1_3 = append(b1_3, 17);
b1_3 = append(b1_3, 18);
b1_3 = append(b1_3, 19);
b1_3 = append(b1_3, 20);
b1_3 = append(b1_3, 21);
//b1_1 = append(b1, 9);
//b1_1 = append(b1, 10);
fmt.Println("b1_1:", b1_1)
fmt.Println("b1_2:", b1_2)
fmt.Println("b1_3:", b1_3)
fmt.Println("b1_3:", len(b1_3))
fmt.Println("b1_3:", cap(b1_3))
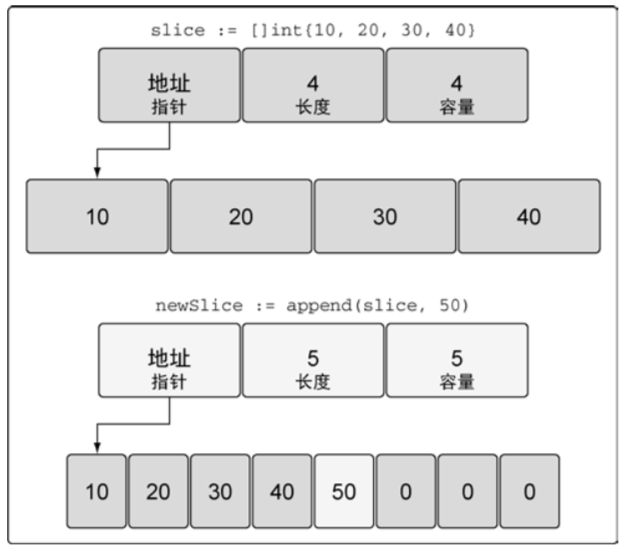
- 当切片容量(而非数组长度,默认切片容量等于数组长度,也可以显示指定)用完了,再追加需要扩容,此处会新建数组,长度为原数组的2倍,然后将旧数组元素拷贝到新数组,newSlice 的底层数组是新数组,newSlice 容量为8;而 slice 的底层数组是旧数组,二者互不影响。
- slice 扩容机制:在切片的容量小于 1000 个元素时,总是会成倍地增加容量。一旦元素个数超过 1000,容量的增长因子会设为 1.25,也就是会每次增加 25% 的容量。
2.4、显示设置容量
在没有显示指定容量的情况下,切片容量就是其底层数组的长度,如果在创建切片时设置切片的容量和长度一样,就可以强制让新切片的第一个 append 操作创建新的底层数组,与原有的底层数组分离。新切片与原有的底层数组分离后,可以安全地进行后续修改
source := []string{"Apple", "Orange", "Plum", "Banana", "Grape"}
// 长度为1=3-2,容量为1=3-2 source[i:j:k] 长度=j-i 容量=k-i
slice := source[2:3:3]
fmt.Println(source) // ["Apple", "Orange", "Plum", "Banana", "Grape"]
fmt.Println(slice) // ["Plum"]
// 超出切片容量3,需要新建数组
slice = append(slice, "Kiwi")
fmt.Println(source) // ["Apple", "Orange", "Plum", "Banana", "Grape"]
fmt.Println(slice) // ["Plum", "Kiwi"]
2.5、合并切片
s1 := []int{1, 2}
s2 := []int{3, 4}
fmt.Println(append(s1,s2...)) // [1, 2, 3, 4]
2.6、迭代切片
slice := []int{10, 20, 30, 40}
// 与数组迭代一样,可以使用 for range + 普通 for 循环
for index,value := range slice {
fmt.Println(index, value)
}
2.7、函数间传递切片
在函数间传递切片就是要在函数间以值的方式传递切片。由于切片的尺寸很小,在函数间复制和传递切片成本也很低;而在函数间传递数组是需要拷贝整个数组的,所以内存和性能上都不好
调用函数,传递一个切片副本,实际上内部还是传递了对数组的指针,所以 foo 内部的操作会影响 main 中的 slice。
import "fmt"
func foo(slice []int) []int {
slice[0] = 100
return slice
}
func main() {
// 1、创建一个 slice
slice := []int{1, 2, 3, 4, 5}
fmt.Println(slice) // [1, 2, 3, 4, 5]
// 2、调用函数,传递一个切片副本,实际上内部还是传递了对数组的指针,
// 所以 foo 内部的操作会影响 main 中的 slice
slice2 := foo(slice)
fmt.Println(slice2) // [100, 2, 3, 4, 5]
fmt.Println(slice) // [100, 2, 3, 4, 5]
}
三、Map 映射
- Map 是一个存储键值对的无序集合,就是说不保证顺序
- Slice、Map、function 以及包含切片的结构类型不能作为 Map 的 key
- map在函数间传递,不会拷贝一份map,相当于是”引用传递”,所以remove函数对传入的map的操作是会影响到main函数中的map的
3.1、基本用法
// 1、使用 make 创建 map,key为string,value为int
map1 := make(map[string]int)
// 2、使用字面量创建 map - 最常用的姿势,key为string,value为slice,初始值中的slice可以不加 []string 定义
map2 := map[string][]string{"hi": {"go", "c"}, "hello": []string{"java"}}
// 3、创建空映射
map3 := map[string]string{} // map3 := map[string]string nil映射
fmt.Println(map1, map2, map3)
// 4、向映射添加值
fmt.Println("map put")
map3["a"] = "x"
map3["b"] = "y"
fmt.Println(map3) // map[a:x b:y]
// 5、获取值并判断是否存在
value, exist := map3["c"]
if exist {
fmt.Println(value)
} else {
fmt.Println("map3[\"c\"] does not exist")
}
// 6、迭代
fmt.Println("iterat")
for key, value := range map3 {
fmt.Println(key, value)
}
// 7、从 map 中删除元素
delete(map3, "a")
fmt.Println(map3) // map[b:y]
以下是我的笔记代码:
m1 := make(map[string]string)
m1["a"] = "A"
m1["b"] = "B"
m1["c"] = "C"
m1["d"] = "D"
fmt.Println(m1)
m2 := map[int]int{}
m2[0] = 100
m2[1] = 100 * m2[0]
m2[2] = 100 * m2[0]
fmt.Println(m2)
parserS1(m1);
//delete(m1,"a")
v, m_1 := m1["a"]
if m_1 {
fmt.Println("存在的", v)
} else {
fmt.Println("不存在的", m_1)
}
for i, n := range m1 {
fmt.Printf("me-> Key %s : %s \n", i, n)
}
3.2、函数间传递映射
import "fmt"
// map在函数间传递,不会拷贝一份map,相当于是"引用传递",所以remove函数对传入的map的操作是会影响到main函数中的map的
func remove(map4 map[int]int) {
delete(map4, 1)
}
func main() {
map4 := map[int]int{0:0, 1:1, 2:2}
fmt.Println(map4) // map[0:0 1:1 2:2]
remove(map4)
fmt.Println(map4) // map[0:0 2:2]
}
F{0XCAB)LKNIT0K@G.gif) 、alue。
、alue。
近期评论