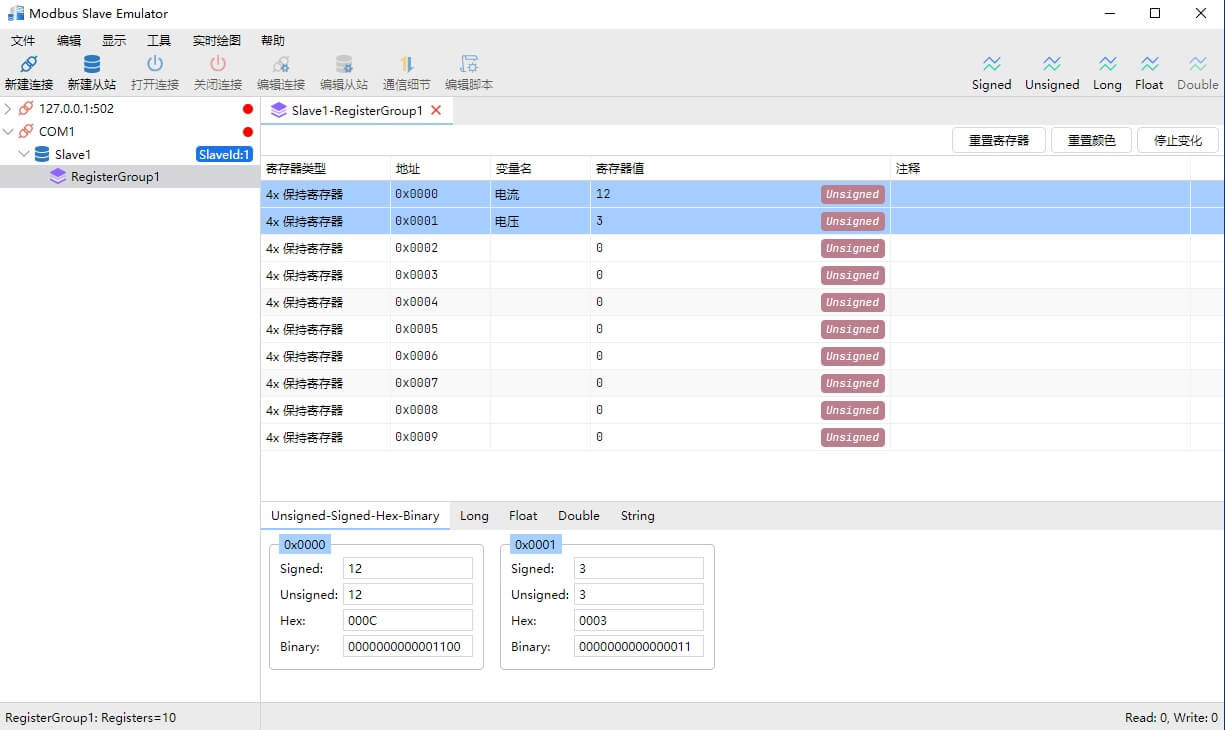
可视化 Modbus 设备中的数据
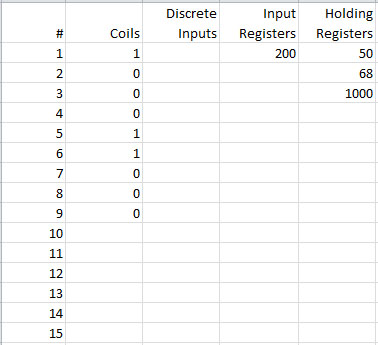
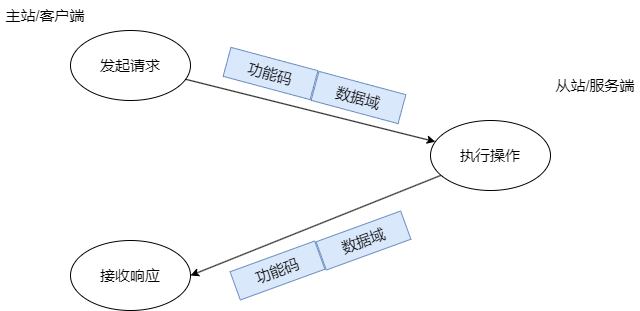
Modbus 从设备可以想象为具有一个内部电子表格,其中填满了数字。Modbus 主设备将向从设备询问其在给定行和列中找到的数据值或数字,从设备将通过将该数据发送回主设备来响应。当然,这个过程可以逆转,Modbus 主设备告诉从设备在给定行和列处将什么数字放入其数据表中。
Modbus 设备“电子表格”中的“列”更正式地称为寄存器类型。寄存器类型可能是线圈、离散输入(又称状态输入)、输入寄存器或保持寄存器。
Modbus 设备“电子表格”中的“行”只是寄存器编号。通常,这些行从 1 开始并按顺序递增。某些设备可能没有寄存器 1,例如,它们的第一个寄存器可能是 100。如果从设备中不存在寄存器编号,它将发回一个异常消息。该异常提供了一个错误代码,提示“没有这样的寄存器”(异常代码 2,非法数据地址)。
什么是 Modbus TCP?
Modbus TCP 将 Modbus RTU 请求和响应数据包封装在通过标准以太网网络传输的 TCP 数据包中。单元号仍包含在内,其解释因应用程序而异 – 单元或从站地址不是 TCP 中的主要寻址方式。这里最重要的地址是 IP 地址,例如 192.168.1.100。Modbus TCP 的标准端口是 502,但如果需要,通常可以重新分配端口号。
TCP 数据包中省略了通常位于 RTU 数据包末尾的校验和字段。对于 Modbus TCP,校验和和错误处理由以太网处理。
Modbus 的 TCP 版本遵循 OSI 网络参考模型。Modbus TCP 定义了 OSI 模型中的表示层和应用层。
Modbus TCP 使主设备和从设备的定义不那么明显,因为以太网允许对等通信。客户端和服务器的定义在基于以太网的网络中更为人所知。在这种情况下,从设备成为服务器,主设备成为客户端。可以有多个客户端从服务器获取数据。在 Modbus 术语中,这意味着可以有多个主设备和多个从设备。现在,系统设计人员的责任是创建主设备和从设备功能之间的逻辑关联,而不是逐个物理设备地定义主设备和从设备。
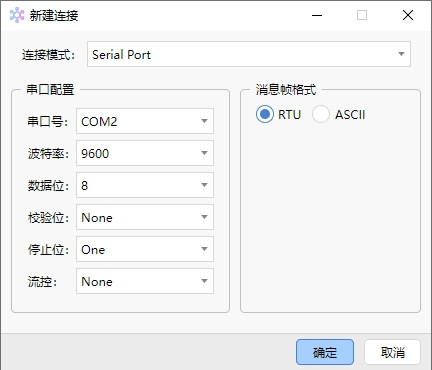
什么是 Modbus ASCII?
Modbus ASCII 是一种较旧的实现,它包含 RTU 数据包的所有元素,但完全以可打印的 ASCII 字符表示。Modbus ASCII 被认为已弃用,很少再使用,并且未包含在正式的 Modbus 协议规范中。
Modbus 寄存器类型回顾
Modbus 设备中引用的寄存器类型包括:
- 线圈(离散输出)
- 离散输入(或状态输入)
- 输入寄存器
- 保持寄存器
特定设备是否包含所有这些寄存器类型取决于制造商。所有 I/O 都仅映射到保持寄存器的情况非常常见。线圈是 1 位寄存器,用于控制离散输出,可以读取或写入。离散输入是用作输入的 1 位寄存器,只能读取。输入寄存器是用于输入的 16 位寄存器,只能读取。保持寄存器是最通用的 16 位寄存器,可以读取或写入,可用于各种用途,包括输入、输出、配置数据或任何“保持”数据的要求。
当网关为主控或以直接模式(Babel Buster SP-GW)运行时,网关将支持所有寄存器类型。将非 Modbus 设备连接到 Modbus 网络的控制解决方案网关在某些情况下将仅使用保持寄存器来表示非 Modbus 设备数据。
大多数控制解决方案 I/O 设备都使用保持寄存器来表示所有类型的输入和输出。在大多数情况下,相同的 I/O 也可以像其他寄存器类型一样访问,并且 I/O 状态或值在多个寄存器中镜像。
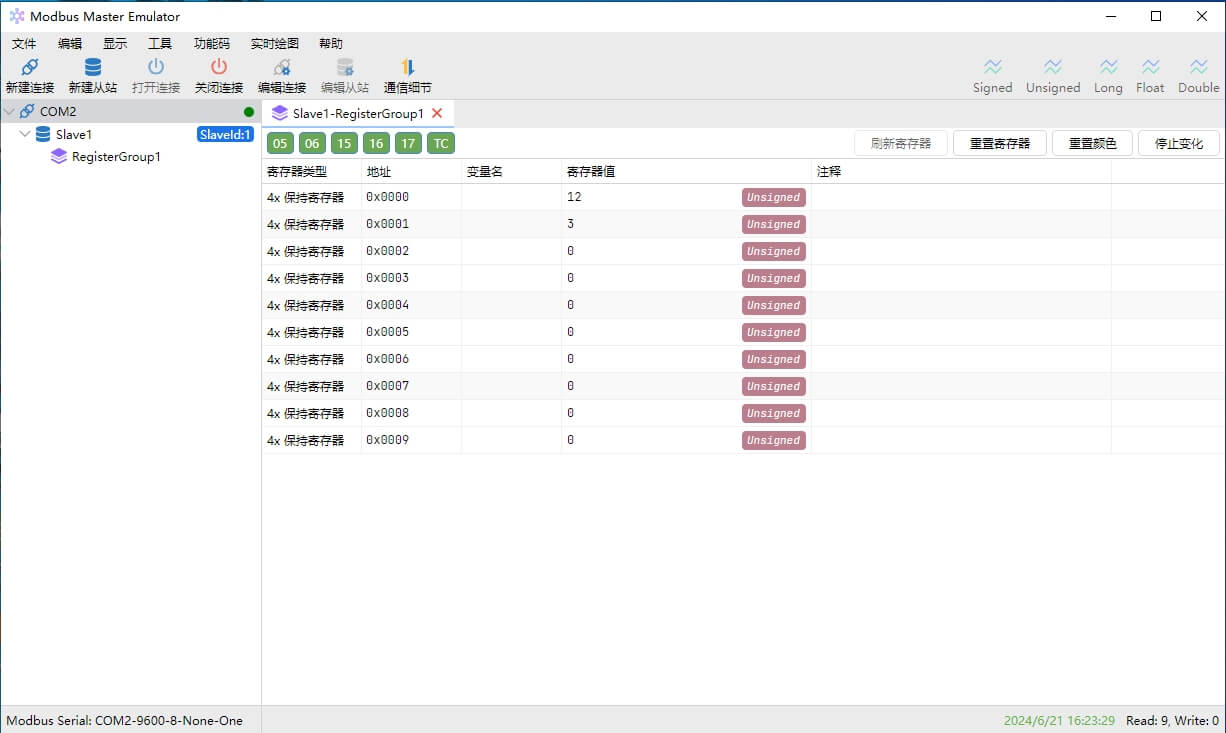
Modbus 功能码
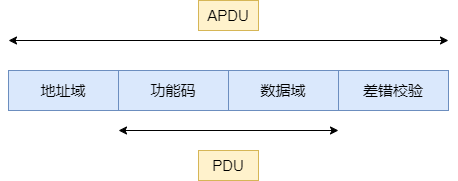
Modbus 协议定义了几个用于访问 Modbus 寄存器的功能代码。Modbus 定义了四个不同的数据块,每个数据块中的地址或寄存器编号重叠。因此,要完整定义在何处查找数据,需要地址(或寄存器编号)和功能代码(或寄存器类型)。
下表列出了 Modbus 设备最常识别的功能代码。这只是可用代码的一个子集 – 其中一些代码具有通常不适用的特殊应用。
| 功能码 | 寄存器类型 |
|---|---|
| 1 | 读取线圈 |
| 2 | 读取离散输入 |
| 3 | 读取保持寄存器 |
| 4 | 读取输入寄存器 |
| 5 | 写入单个线圈 |
| 6 | 写入单个保持寄存器 |
| 15 | 写入多个线圈 |
| 16 | 写入多个保持寄存器 |
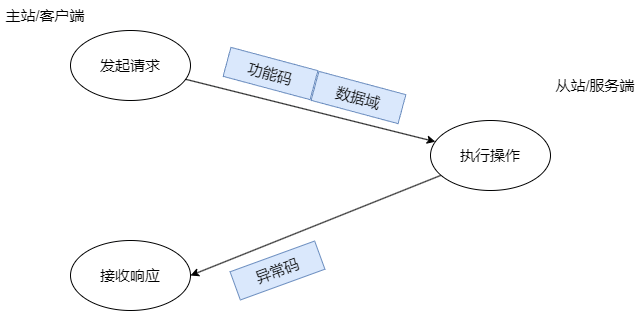
Modbus 异常(错误)代码
当 Modbus 从站识别出数据包,但确定请求中存在错误时,它将返回异常代码回复,而不是数据回复。异常回复由从站地址或单元号、设置了高位的功能代码副本和异常代码组成。例如,如果功能代码为 3,则异常回复中的功能代码将为 0x83。异常代码将是以下之一:
| 异常码 | 说明 | 详细说明 |
|---|---|---|
| 1 | 非法的功能码 | 查询中收到的功能代码不被从站识别或不被从站允许。 |
| 2 | 非法的数据地址 | 查询中收到的数据地址(寄存器编号)不是从站允许的地址,即寄存器不存在。如果请求多个寄存器,则至少有一个寄存器不被允许。 |
| 3 | 非法的数据值 | 查询数据字段中包含的值对于从站来说是不可接受的。 |
| 4 | 从设备故障 | 从站尝试执行请求的操作时发生不可恢复的错误 |
| 6 | 从设备忙 | 从属设备正在处理一个长持续时间的命令。主设备应稍后重试。 |
| 10 | 网关路径不可用 | 与网关结合使用的专门用途,通常意味着网关配置错误或超载 |
| 11 | 网关目标设备无法响应 | 专门与网关结合使用,表示未从目标设备收到响应。 |




近期评论